

This article provides a comprehensive exploration of the splitting criteria used in decision trees for classification and regression. It highlights the importance of selecting the appropriate criterion for optimal predictive performance. By understanding the strengths, weaknesses, and considerations involved in choosing a splitting criterion, readers will gain valuable insights into enhancing the performance of their decision tree models. Whether you are a data scientist or simply interested in decision tree algorithms, this guide equips you with the knowledge to navigate and optimize decision tree splitting for classification and regression tasks.
Splitting Criteria For Decision Trees : Classification and Regression
Used in the recursive algorithms process, Splitting Tree Criterion or Attributes Selection Measures (ASM) for decision trees, are metrics used to evaluate and select the best feature and threshold candidate for a node to be used as a separator to split that node.
- For classification, we will talk about Entropy, Information Gain and Gini Index.
- For regression, we will talk about variance reduction: Mean Squared Error (MSE), Friedman MSE,Poisson Deviance, Mean Absolute Error (MAE).
In the following, we will explore each criterion for both tasks classification and regression.
Classification criteria
Entropy
Entropy is a measure, as average, of the uncertainty of the possible outcomes of a random variable. This measure reflects how impure the subset is.
To measure the impurity, we need to measure the proportion of each class on the subset. If there is a majority of one class among others, the subset is pure and the entropy is small. The feature leading to this pure subset will be selected to split the node. Inversely, if there are large proportion of two or 3 classes in the same subset, the entropy is high. Therefore, we will not select the feature.
The entropy formula is:

Important: in Scikit-learn log-loss is also a type of entropy. Both methods are triggering entropy computation.
Information Gain
The formula is:
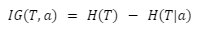
with:
- T: a set of training data
- H(T) : Is the entropy of this training dataset
- H(T|a) : Is the entropy of this set given a condition on the attribute a. This attribute is one of the features in the training dataset.
The information gain is based on how much information we gain by using one or another feature of the dataset. It computes the reduction of entropy on T by using the feature a. The bigger is the entropy reduction, the bigger is the information value and the better is the feature to use for the current split in the current node.
Gini Index or Gini Impurity
The Gini Impurity concept is very related to the entropy one. This metric measures the impurity of a dataset. The more impure the dataset, the higher is Gini index.
The term “impurity” in this context reflects the inclusion of multiple classes within a subset. As the number of unique classes present in the subset increases, the impurity value also rises accordingly.
The formula:

Where:
- C: The number of classes included in the subset
- i: The class i, with i {1, 2, 3, ….C}
- pi : The proportion of the class “i” is in the subset.
In the upcoming section, we will delve into the splitting criteria employed specifically in regression tasks.
Regression criteria
When the target is continuous, the predicted value of a terminal node could be:
- The mean value of the subset of this node (y), for Mean Squared Error and Poisson deviance.
- The median value for Mean Absolute Error: median(y)
Mean Squared Error (MSE)
The goal of this measure is to minimize the L2 distance, which is the squared difference between all values contained in a node and the mean value of this node. It is also known as Variance Reduction.
We talk also about Residual Sum of Squares (RSS), where the predicted value at each time is the mean value of the node.
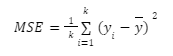
With:
- k : The number of observations in a node
- y : The mean value of k target values yi in this node
The lowest the value is, the better the feature and the best threshold is to split the node.
Poisson Deviance
The formula is :
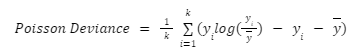
To use Poisson Deviance, yi must be positive. It fits much slower than MSE.
Friedman MSE
Friedman MSE criteria computes also a mean squared error for each with an impurity improvement score.
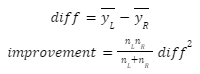
With:
- yL : The mean value on the left side of the node
- yR : The mean value on the right side of the node
- nL: The number of observations on the left side of the node
- nR: The number of observations on the right side of the node
The separator of the node will be the feature that maximizes this score.
Mean Absolute Error (MAE)
The goal is to minimize the L1 distance between the target values yi in a node and their median.

With median(y1,2..k) is the median value of the node, composed of k observations.
It fits much slower than MSE.
The lowest the value is, the better the feature and the best threshold is to split the node.
Summary
Throughout this article, you have gained knowledge about various splitting criteria employed in constructing decision trees for both classification and regression purposes. Each criterion has been accompanied by a formula and a detailed explanation of its underlying intuition, providing you with deeper insights into their practical applications. If you wish to explore the step-by-step process of building a decision tree using these criteria, we invite you to explore our supplementary articles, where we provide in-depth explanations starting from the ground up.
I hope you found value in this article. Your comments and feedback are highly appreciated as they contribute to the continuous improvement of the content provided. Please feel free to leave a comment below 👇 to share your thoughts and insights.


