

In this post, you will learn all what you need about Information Gain metric:
- The definition and the intuition behind,
- How is it calculated?
- How is it related to Entropy?
- How is it used in Decision Trees classification?
- How is it computed, step by step, using a practical example, to build a tree?
What is Information Gain (IG)?
Information gain is a concept derived from Information Theory (like Entropy).
In the machine learning field, the information gain (IG) is used in decision trees classification to decide on the best feature to consider to split each node of the tree.
It’s computed using the entropy concept explained clearly in this article.
I Highly recommend to read this article before, to understand what Entropy means and how it is calculated
The Information Gain metric is used in the following algorithms: ID3, C4.5 and C5.0 (ID3 extension) used to build the decision trees.
In the following, you will discover its formula and the intuition behind.
Mathematical Formula
The information Gain is the difference between the Entropy of a dataset in a node of a subtree, and the weighted average entropies generated by using a given feature and threshold as a separator for this node. Here is the formula:
IG(T,a) = H(T) – H(T|a)
with:
- T: a set of training data
- H(T) : Is the entropy of this training dataset
- H(T|a) : Is the entropy of this set given a condition on the attribute a. This attribute is one of the features in the training dataset.
Intuition
The information gain is based on how much information we gain by using one or another feature of the dataset. The bigger is the information value, the better is the feature to use for the current split in the current node.
In other words, information gain computes the reduction of entropy on T by using the feature a. This is what we also call Mutual Information. The greater this reduction is, the higher is the Information Gain, the better is this feature as a classifier.
What is the role of Information Gain (IG) in the Decision Trees model?
To build a tree using Information Gain metric, you need
For each node:
- Compute the entropy before the split
- For each feature, in the current node:
- Compute the weighted average value of the entropy generated by the split.
- Compute the information gain as the difference between the entropy of the node before the split and the average entropy after the split.
- Sort the Information Gain for all the features and keep the highest value. Thus gives the best feature to use for the current node
- Go to the next node, and repeat the above steps
- Stop the splitting once the stop criteria of the tree is met.
Practical example
Let’s take the same dataset as in the entropy chapter to understand how we compute this metric.

They are fake data, built just for illustration
Consider a scenario where a bank collects this dataset with the intention of assigning scores to clients.
A client having a good credit note, will have access to a loan with the bank. And the client, having a bad note, will see his request refused by the bank.
The goal is to predict the credit note of a client, based on his/her information: savings, assets, and salary.
We want to build a tree for this dataset. The first question is what would be the best feature (Savings, Assets, Salary) to begin with and put in the root node?
First we need to compute the general entropy for the root node, which is the general entropy for the whole dataset:
General Entropy
Here is how we compute the entropy of this dataset:
- We have 4 “Good” notes and 3 “Bad” notes.
- The probability to have a “Good” note is:

- It’s entropy is:
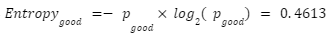
- The probability to have a “Bad” note is:

- It’s entropy is
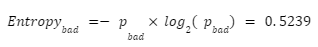
The general Entropy of this dataset is:

Now let’s consider the first feature Savings as a candidate to split the root node, and let’s compute its information gain:
Feature 1 – Categorical: Savings

The entropy computed based on the Savings split, is equal to 0.464.
Thus the information gain for this split is:
- H(T) = 0.985
- H(T|a) = 0.464
- IG(T,a) = H(T) – H(T|a) = 0.522
Pretty much an important reduction of entropy, and greater information value.
For Assets, if you follow the same logic, you will find an information Gain about 0.02: very small reduction of entropy. Assets feature is not giving valuable information value to classify credit notes. Therefore, we will not chose it. For the moment Savings feature has the largest value.
Now, Let’s compute the Information Gain for Salary, the only continuous feature in our dataset. In the Entropy article you will see how we compute the different thresholds for a continuous variable. In the following, let’s do it for the threshold $27.5.
Feature 2 – Continuous: Salary
Here is the subtree of Salary feature with threshold $27.5K:
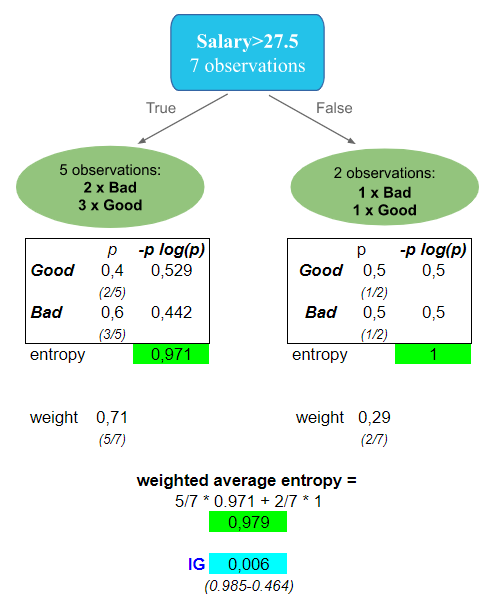
The information Gain is 0.006. There is almost no information value gained. This is the worst feature to begin with.
Now that you understand how we compute the information gain:
- You can do it for other remaining features/values for the root node.
- You sort the Information Gain, to keep the largest value. You have now the first candidate for the root node.
If you have done the exercise, you will find that Savings was the best candidate for the root node.
Now our first node looks like:
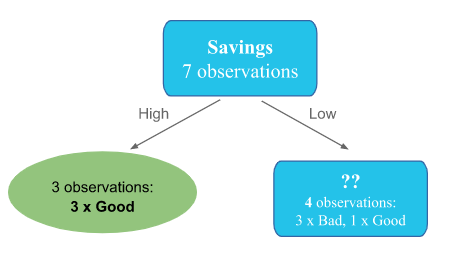
The left side is a leaf because we only have 3 observations that are all good.
But for the right side, you need to figure out which feature to use in this node.
To do that, you need first to compute the entropy of this new subset:

Then consider the different features on this subset one by one, by following the above method to compute the Information Gain.
Let’s do it for one feature, Assets, and I let you do it for the others.
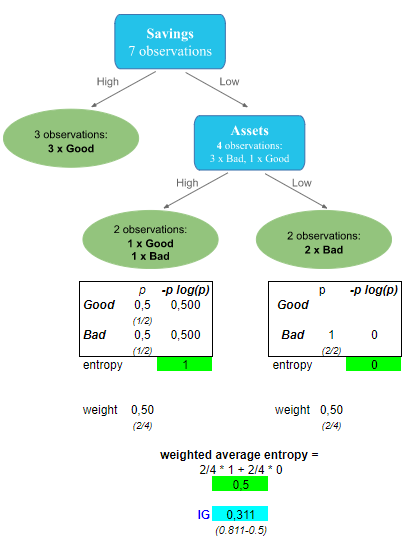
For Assets, the IG = 0.311.
Now, you need to do it for the other features and choose the one with the highest IG value.
Summary
Important thing to remember: The larger the value of Information Gain of a subtree, the better is the reduction of entropy, and the better is the feature (and its value) used to split the node of this tree.
You can have a look also on the GiniIndex article, in which you will find a detailed explanation of the metric used for decision trees classification.
In this article, you have learned about Information Gain metric, used in decision trees classification:
- Its definition
- Its relationship with Entropy
- Its mathematical formula
- How to use it to build a tree: Its computation, step by step, feature by feature using an example of a dataset
I hope you enjoyed reading this article.
Tell me what did you think about this article in the comments, I appreciate your feedback 👇.


