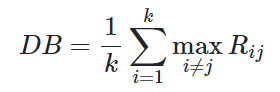When it comes to clustering subject using k-means model, one of the most important question is how to choose K the optimal number of clusters? In this article, you will learn the 3 must-know methods to find this optimal K for K-means clustering .
There are many ways to handle this question. One of the most famous solution is the Elbow method. However, when applied to datasets in the real world, it does not really help to choose explicitly the best K. That’s why I will introduce in this article 3 methods, when combined, it will definitely help to reach our objective.
How To Find The Optimal Number of K for K-Means Clustering? The 3 Must-Know Methods
In the following, I describe the 3 must-know methods to find the optimal K for k-means clustering:
Silhouette score
Calinski-Harabasz Index
Davies-Bouldin Index
Silhouette score
The Silhouette coefficient measures how far the clusters are distant to each other. The highest value shows that the clusters are dense and well separated.
The score within an interval of [-1,1]: 1 is the best score, and indicates that the clusters are far away one from another. 0 shows that the clusters are near one to another or overlapping. And negative value -1 indicates that the sample is allocated to the wrong clusters.
The Silhouette coefficient is computed for each sample using two measure of distance:
a: The mean distance between the sample and all other points within the same cluster (intra-cluster distance)
b: The mean distance between the sample and all other points within the nearest cluster that the sample is not a part of (Inter-cluster distance)
The global Silhouette coefficient is the mean of each sample Silhouette coefficient.
Illustration of the Silhouette score mechanism
Calinski-Harabasz Index
Is also known as Variance Ratio Criterion. The score is defined as the ratio of the mean of between-cluster dispersion and of within-cluster dispersion of all clusters (where the distance is calculated as the sum of squared distances).
When the between-cluster dispersion is high, the clusters are well separated. When the within-cluster dispersion is low, the clusters are dense.
Thus, a higher score indicates well separated and dense clusters.
,
With E the dataset of size , which has been clustered into k clusters. Cq is the number of data points in cluster q. is the center of cluser q. is the center of the datase E. is the number of points in the cluster q.
Illustration of Calinski-Harabaszindex mechanism
Davies-Bouldin Index:
The index is calculated as the average similarity between each cluster and its most similar one, where the similarity is the ratio of within-cluster distances to between-cluster distances.
A lower score indicates a better separation between clusters. The score is nonnegative and a value closer to zero indicates a better partition.
: The mean distance for each point within the cluster i and its center
: The distance between the centers of the clusters i and j
for i=1,…,k with k number of clusters
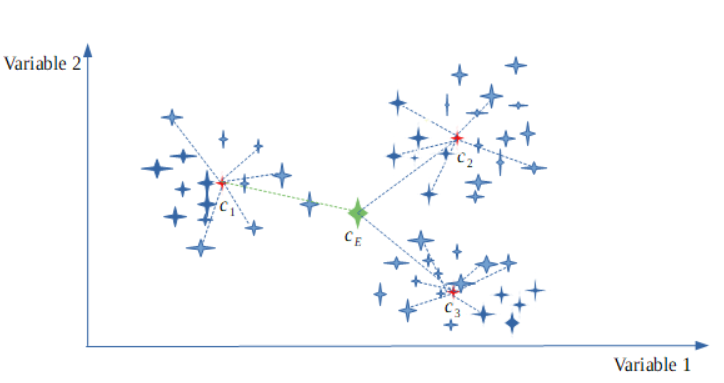
Illustration of Davies-Bouldinindex mechanism
Summary
In this article, you have learned:
These 3 must important methods that help finding the optimal number of K in K-means Clustering model:
Silhouette Score
Calinski-Harabasz Index
Davies-Bouldin Index
Their mathematical formulas
An Illustration to visulualize the concept of each metric
I hope you enjoyed learning my article.
Did you already use one of these metrics? Which one? leave me a comment to share your feedback👇.




,

: The mean distance for each point within the cluster i and its center
: The distance between the centers of the clusters i and j