Start now learning how to get into ChatGPT API using Python. Learn how to create the OpenAI API Key, how to make your first call and what are the different parameters to use in ChatGPT API to customize your prompts.
OpenAI API
API Key
First, you need to sign up for the OpenAI API or ChatGPT API and create an API Key. This key will be used in the OpenAI Python library called “openai”.
Have a look at the section at the end of the article “Manage Account” to see how to connect and create an API Key.
Install “openai”
Install OpenAI client library “openai” by launching this command:
pip install openaiImport “openai”
Import “openai” and set up the API key you get from step one:
import openai
openai.api_key = "YOUR_API_KEY"Or if you put it in your environment variables:
import os
import openai
openai.api_key = os.getenv("YOUR_API_KEY")Ready to make a call request in ChatGPT API in Python
Now you are ready to use the ChatGPT API to make your first call using Python.
Let’s use the method openai.ChatCompletion.create() to create a conversation with ChatGPT.
response=openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[{"role":"user",
"content":"What are the different types of machine learning models?"}
]
)In this method, we specify a model and messages object:
- Model: “gpt-3.5-turbo” is the model currently available in ChatGPT API
- Messages: The messages object is a list of dictionaries. Each dictionary is composed of a role and a content.
- Role: In our case, we use the “user” role as we are the ones requesting the information. I will detail hereafter the other roles and how to use them.
This method will give the same results as if you are using the GUI.
Get the response
The response from the API call will be a JSON object:
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "There are various types of machine learning models which are broadly categorized as follows:nn1. Supervised learning models: These models are trained using labeled data, which is used to predict output for new, unseen data. Examples of supervised learning models include regression, decision trees, random forests, support vector machines (SVM), naive Bayes, and neural networks.nn2. Unsupervised learning models: These models are trained using unlabeled data, which is used to identify patterns and relationships in data. Examples of unsupervised learning models include clustering, dimensionality reduction, and association rule learning.nn3. Semi-supervised learning models: These models are trained using a combination of labeled and unlabeled data, which is used to improve the accuracy of the modelu2019s predictions. Examples of semi-supervised learning models include self-training and co-training.nn4. Reinforcement learning models: These models learn through trial and error by receiving feedback in the form of rewards or punishments for their actions. Examples of reinforcement learning models include Q-learning and deep reinforcement learning.",
"role": "assistant"
}
}
],
"created": 1680543677,
"id": "chatcmpl-71IT7as7GC2rvHzkGip0mm3NxycLy",
"model": "gpt-3.5-turbo-0301",
"object": "chat.completion",
"usage": {
"completion_tokens": 208,
"prompt_tokens": 18,
"total_tokens": 226
}
}As you can see, there are a lot of informations there, but the most important one is contained in response.choices[0].message.content:
print(response.choices[0].message.content)There are several types of machine learning models, including:
1. Supervised learning models: These models are trained on labeled data and are used to predict outcomes for new, unseen data. Examples include linear regression, logistic regression, decision trees, and random forests.
2. Unsupervised learning models: These models are trained on unlabeled data and are used to find patterns and relationships in the data. Examples include clustering algorithms, such as k-means and hierarchical clustering.
3. Semi-supervised learning models: These models are trained on a combination of labeled and unlabeled data and are used when there is not enough labeled data to train a supervised model. Examples include self-training and co-training algorithms.
4. Reinforcement learning models: These models learn by interacting with an environment and receiving feedback in the form of rewards or penalties. Examples include Q-learning and deep reinforcement learning.
5. Deep learning models: These models are a subset of neural networks and are used for complex tasks such as image and speech recognition. Examples include convolutional neural networks (CNNs) and recurrent neural networks (RNNs).Awesome, no? As you can see it gives an interesting and correct answer about the different types of machine learning models.
Now let’s go further in the API call.
Go Further: Roles
There are 3 types of roles: user, assistant, system.
- The one you and I are using is “user” (the prompt in the GUI), as seen before.
- The role “assistant” acts like a memory for chatGPT or as enrichment. In the content of this role, you will provide the past answers to let chatGPT track the conversation history, and give you responses related to what it just answers, to be more consistent (In the same way as with the interface). (see next paragraph)
- The role “system” concerns the instruction you give to the assistant to follow. (See Instruction : “System” role)
Assistant role: Let “openai” remember your past conversation:
When I askedChatGPT the different types of machine learning models, I stored the answer in the variable “first_message”:
response=openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[{"role":"user",
"content":"What are the different types of machine learning models?"}
]
)
first_message=response.choices[0].message.contentThen, I asked him to give the explanation of one example model in each category:
response=openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[{"role":"user",
"content":"Give me an explanation of one example model for each category that you just gave"}
]
)
second_message=response.choices[0].message.content
print(second_message)Here is its answer:

There is clearly no relationship between both requests. ChatGPT did not store the first answer.
Now, let’s give more context by specifying the role “assistant” and the first answer as a content:
response=openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[{"role":"assistant", "content":first_message},
{"role":"user",
"content":"Give me an explanation of one example model for each category that you just gave"}
]
)
third_message = response.choices[0].message.content
print(third_message)Here is the answer: Isn’t it awesome?
Sure, here are some examples of machine learning models for each category:
1. Supervised learning model: Decision Trees - Decision trees are a type of supervised learning model that can be used for both classification and regression tasks. They work by recursively splitting the data into smaller subsets based on the most important features until a decision is made.
2. Unsupervised learning model: K-Means Clustering - K-means clustering is a type of unsupervised learning model that is used to group similar data points together. It works by randomly assigning data points to clusters and then iteratively refining the clusters until the data points are grouped together in the most optimal way.
3. Semi-supervised learning model: Co-Training - Co-training is a type of semi-supervised learning model that is used when there is not enough labeled data to train a supervised model. It works by training two separate models on different subsets of the data and then using the predictions from one model to label the data for the other model.
4. Reinforcement learning model: Q-Learning - Q-learning is a type of reinforcement learning model that is used to learn optimal policies for decision-making tasks. It works by updating a Q-table that stores the expected rewards for each action in each state, based on the feedback received from the environment.
5. Deep learning model: Convolutional Neural Networks (CNNs) - CNNs are a type of deep learning model that are commonly used for image recognition tasks. They work by using convolutional layers to extract features from the input image and then passing these features through fully connected layers to make a prediction.Here is one step further: I want to get a Python code example of each model mentioned above:
response=openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[{"role":"assistant", "content":third_message},
{"role":"user",
"content":"Give me a python code example for each of them"}
]
)
fourth_message = response.choices[0].message.content
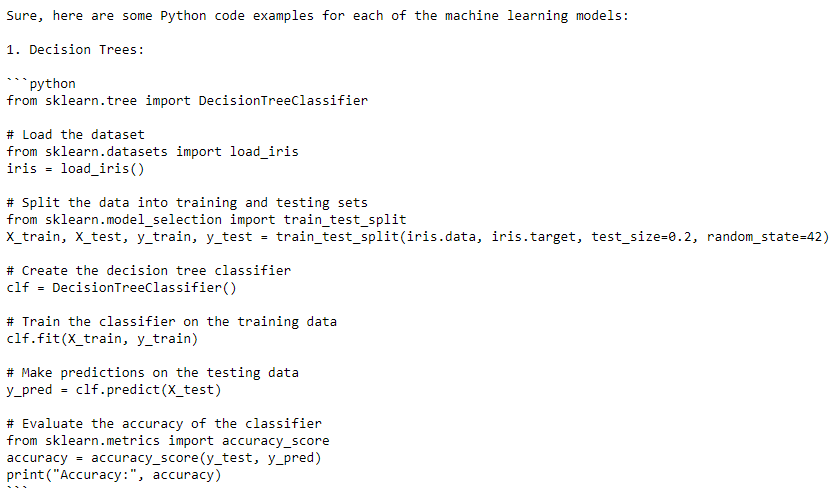
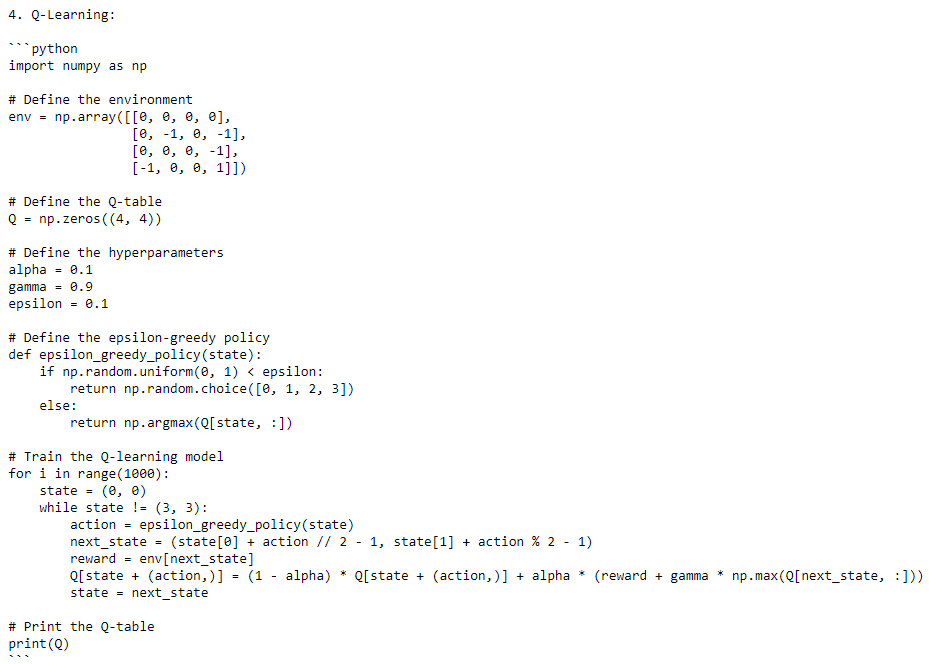
print(fourth_message)The AI gives me a python code for each model : Decision Trees, K-Means Clustering, Co-Training, Q-Learning, and the CNN. For each one, I get a dataset to load, a split between train and test sets, a fitting of the model, a prediction and the accuracy calculation. Once more, this is brilliant!
Here is an overview of 2 answers (can’t put the whole details): Decision Trees (Answer 1) and Q-learning model (Answer 4):
If I didn’t precise the content of the assistant role, here is the answer I get:
response=openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{"role":"user",
"content":"Give me a python code example for each of them"}
]
)
fourth_message = response.choices[0].message.content
print(fourth_message)Nothing to do with previous conversations.

System role: Give instruction to the AI
Using the role : “system”, you can instruct to the AI a lot of things, for example:
- Let’s think step by step
- You are a helpful assistant that translates English to French
- Let’s be consistent and concise
- Let’s summarize like a story
- …
However as said in the documentation, gpt-3.5-turbo does not pay strong attention to the system message. This message can be incorporated directly in the user’s content. But I still use it separately, and the results are just brilliant!
Here I ask ChatGPT to explain to me how Gradient Boosting is built:
response=openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{"role":"system", "content":"Let's think step by step"},
{"role":"user",
"content":"Explain to me how Gradient Boosting is build"}
]
)
print(response.choices[0].message.content)This gives a general idea how the Gradient Boosting is working: This is a good start

However, I want him to be more specific:
response=openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{"role":"system", "content":"Let's think step by step and be concise and consistent"},
{"role":"user",
"content":"Explain to me how Gradient Boosting is built"}
]
)
print(response.choices[0].message.content)It’s just a brilliant summary of the algo (I put it in a plain text, so you can use it):
Gradient Boosting is a machine learning algorithm that builds an additive model in a forward stepwise manner. The algorithm combines multiple weak models, usually decision trees, to form a stronger model. It does this by iteratively improving the model s predictions by minimizing the errors in the predictions made in the previous iteration.
Here are the steps to build a Gradient Boosting model:
1. Initialize the model by setting the predicted value to be equal to the mean value of the target variable.
2. Train a weak model, usually a decision tree, to predict the residual error (difference between the predicted and actual value) from the previous iteration.
3. Add this weak model to the existing model by multiplying it by a small learning rate (also called the shrinkage factor) and adding it to the previous predicted value.
4. Repeat steps 2 and 3 until the desired number of iterations is reached or the model s performance metric reaches a plateau.
5. Once the model is trained, it can be used to predict the target variable for new data by running the data through the series of weak models and adding the predictions.
6. The model's performance can be evaluated using a suitable metric such as Mean Squared Error (MSE) or Area Under the Curve (AUC).
7. Hyperparameter tuning can be employed to select the optimal values for the learning rate, maximum depth of the trees, and number of iterations, amongst other parameters.FUNNIEST part: Here let’s be funny, I asked the AI to summarize Gradient Boosting as a story:
response=openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{"role":"system", "content":"Let's summarize like a story"},
{"role":"user",
"content":"Explain to me how Gradient Boosting is built"}
]
)
print(response.choices[0].message.content)“ Once upon a time in the world of machine learning, there was a popular algorithm called Gradient Boosting. It was known for its ability to create powerful predictive models on large datasets with many features.
To build Gradient Boosting, the algorithm starts with a simple model, like a decision tree, and uses it to make predictions on the training data. It then calculates the difference between the predicted values and the true values, which are also known as residuals.
The next step is to build another model that predicts these residuals. This new model is also known as a weak learner and is trained on the same features as the first model.
The two models are then combined, with the second model's predictions added to the first model's predictions. This creates a new set of predictions that takes into account the residuals from the previous model.
This process is then repeated multiple times, with each new model built on the residuals of the previous model, until the algorithm has reached a specified number of models or until further improvements to the model are not possible.
The final predictions are made by taking the sum of all the predictions made by all the models in the algorithm. This creates a powerful ensemble model that is able to consistently make accurate predictions on new, unseen data.
And that, my friend, is how Gradient Boosting is built.”Manage Account and get the API Key to use in ChatGPT API Python
If you don’t have an account, create one.
- Go to Personal at the top right:

- Click on Manage Account
- Get the API Key
On the left side menu, click on API Keys
- Click on “Create new secret key:
Keep it well somewhere. If you lose it, you can’t find it, you need to create a new one.
- Usage Tab
You can have a look on the Usage tab: Here you will have general information of how much the API calls cost you per day. For each API call, you pay only a very tiny cost (0.005$)
Your account is granted with a free Trial up to 18$ during one month:

Summary
In this article, you have learned:
- How to install ChatGPT API – openai and set up you account and API Key
- How to use use it by making your first call, with “user” role
- How to go further by acting on the both roles assistant and system