
In 2023, there was considerable buzz around AI, as it achieved widespread adoption and became an integral part of our daily lives. However, this transformation didn’t happen overnight; it’s the result of decades of relentless research, technological advancements, and innovative breakthroughs. In this article, we’ll delve into the key factors in AI’s advancement: From significant research papers and quantization techniques to GPU innovations.
We’ll begin with a look at the landmark research papers in Large Language Models (LLMs), highlighting the most important research papers that bring groundbreaking ideas and push the boundaries of natural language processing (NLP). These papers are not just academic achievements; they are THE building blocks of the digital assistants, translation services, and content generation tools we use every day.
Next, we’ll talk about quantization, a key technique that has significantly sped up and enhanced the efficiency of training and deploying LLMs. The evolution of quantization techniques is making AI more accessible and sustainable, especially in resource-constrained environments.
Finally, we’ll dive into the world of GPU (Graphics Processing Units) advancements allowing rapid processing of neural networks.
Before we start, one factor contributing to the success of AI is its user-friendly applications, such as chatbots, which facilitate interaction for everyone. These applications make complex models accessible to non-experts, enabling people outside the scientific community to discover practical use cases that enhance their daily work and lives.
Not to mention that, even before 2023, AI’s impact extended across multiple domains beyond chat applications, including healthcare, finance, transportation, and more.
Glossary at the end of the ebook.
Research Papers Contributing to LLMs Development
Key Research Papers
Here are the key research papers that have played a significant role in advancing AI and integrating it into everyday life (all papers are not listed):
1. “ImageNet Classification with Deep Convolutional Neural Networks”
by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton (2012):
This is the foundational paper for AlexNet, which brought significant advancements in deep learning for image classification.
https://papers.nips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
2. “AlexNet”
By Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton (2012):
This paper introduced AlexNet, a deep convolutional neural network that significantly outperformed other models in the ImageNet competition and won it. It played a major role in popularizing deep learning in image recognition and computer vision.It popularized the use of Convolutional Neural Networks (CNNs) and accelerated the application of deep learning.
http://www.cs.utoronto.ca/~ilya/pubs/2012/imgnet.pdf
3. “Playing Atari with Deep Reinforcement Learning”
By Volodymyr Mnih et al. (DeepMind, 2013):
This paper marked a significant advancement in applying deep learning to reinforcement learning, opening up new possibilities for AI in games and simulations.
https://arxiv.org/abs/1312.5602
4. “Generative Adversarial Nets”
By Ian Goodfellow et al. (2014):
This paper proposed the concept of Generative Adversarial Networks (GANs), a novel framework for estimating generative models, significantly impacting the field of generative models in AI.
https://arxiv.org/abs/1406.2661
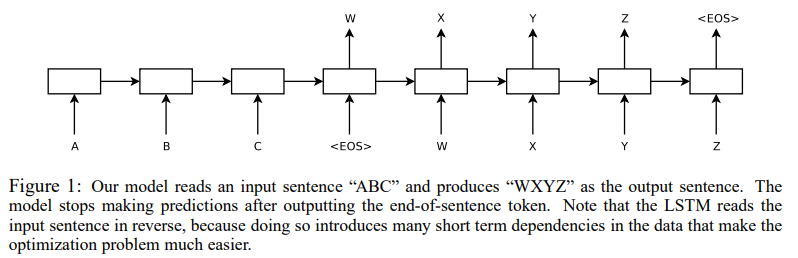
5. “Sequence to Sequence Learning with Neural Networks”
By Ilya Sutskever, Oriol Vinyals, and Quoc V. Le (2014):
This paper was crucial in developing models for tasks like machine translation, where an input sequence (like a sentence in one language) is transformed into an output sequence (like a sentence in another language).
https://arxiv.org/abs/1409.3215
6. “A Neural Algorithm of Artistic Style”
By Gatys, Ecker, and Bethge (2015):
This paper introduced neural style transfer, showing how deep neural networks could recreate images in the style of famous artworks, bridging the gap between AI and creative arts.
https://arxiv.org/abs/1508.06576
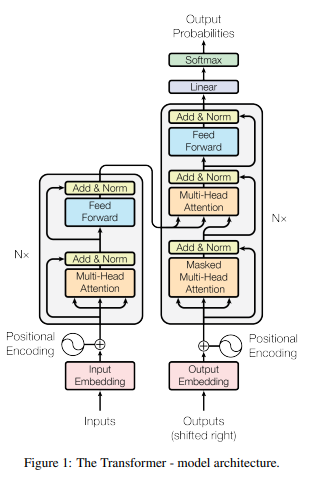
7. “Attention Is All You Need”
By Ashish Vaswani et al. (2017) (last modification from Aug 2023):
This paper introduced the Transformer model, which revolutionized natural language processing. The Transformer model is the basis for many subsequent models, including GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers).
https://arxiv.org/abs/1706.03762
8. “Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm”
By Silver et al. (DeepMind, 2017):
This paper introduced AlphaZero, demonstrating remarkable performance in board games like chess and shogi through self-play and deep reinforcement learning.
https://arxiv.org/abs/1712.01815
9. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”
By Jacob Devlin et al. (2018):
This paper from Google introduced BERT (Bidirectional Encoder Representations from Transformers), which improved the way neural networks handle context in natural language processing, impacting search engines and many NLP applications.
https://arxiv.org/abs/1810.04805

10. “Large Scale GAN Training for High Fidelity Natural Image Synthesis”
By Andrew Brock, Jeff Donahue, and Karen Simonyan (2018):
This paper introduced BigGAN, advancing the capabilities of GANs in generating high-resolution, realistic images.
https://arxiv.org/abs/1809.11096
These papers represent key milestones in AI research, each contributing significantly to the development of the field and its integration into various aspects of technology and everyday life.
GPTs model releases chronology
With GPT (Generative Pre-Trained Transformer) models gaining significant popularity over the past year, here’s a chronology of the GPT models released by OpenAI:
- GPT-1: Introduced in June 2018, GPT-1 was OpenAI’s first transformer-based language model. It had 117 million parameters and was a significant advancement in language models at the time.
- GPT-2: Released in February 2019, GPT-2 marked a substantial increase in scale with 1.5 billion parameters. It was trained with data from the internet and could perform a broader range of tasks without specific training. OpenAI initially released smaller versions of this model due to concerns about potential misuse.
- GPT-3: Released in 2020, GPT-3 significantly expanded on the capabilities of its predecessors with 175 billion parameters. It was not released as an open-source model; instead, OpenAI provided public access through an API.
- GPT-3.5: Known as the model behind ChatGPT, GPT-3.5 is a fine-tuned version of GPT-3 that improved upon its capabilities, especially in understanding and generating natural language and code.
- GPT-4: Released to ChatGPT Plus paid subscribers in March 2023, GPT-4 brought further improvements, especially in handling complex tasks, and expanded the context window significantly.
- GPT-4-Turbo, GPT-4-Turbo With Vision: Released in November 2023, and announced during its first DevDay ever on November 06, 2023. It’s a multimodal capable of accepting text or image inputs.
For detailed information, you can refer to the sources from :
https://en.wikipedia.org/wiki/OpenAI#Generative_models
Or you can read this article, which I find interesting: https://generativeai.pub/a-look-into-the-evolution-of-gpt-models-from-gpt-1-to-gpt-4-38b68c2f275b
Concerns
While the foundational papers in AI have been instrumental in advancing both the field and its practical applications, it’s important to consider the broader context of academic research and publication.
In 2023, a significant number of research papers were published. However, within the current publishing landscape, there exists a discord between the pressure to publish and the academic sector’s aspiration for impactful scholarship. This rush to publish has led to the emergence of papers with findings that are false, dubious, or unreplicable. Consequently, in 2023, more than 10,000 research papers faced retraction – setting a new record and raising serious concerns about public trust in scientific research.
Quantization and its role in AI
Main Contributions
Quantization, in the context of artificial intelligence and machine learning, refers to the process of reducing the precision of the numbers used in a model’s calculations. Typically, this involves converting floating-point numbers (which have a high precision) to integers (which have lower precision). From 32-bit floating-point to 16-bit floating-point or 8-bit integer numbers.
The main goals and contributions of quantization are:
- To speed up both training and inference times because it requires less computational resources thanks to the precision reduction.
- To make it possible to deploy complex AI models in limited memory and computational power devices like smartphones, IoT devices, and embedded systems.
- To lower energy consumption which is crucial for battery-powered mobile devices and for the overall energy footprint of AI computations.
- To democratize AI usage by enabling AI models to run on less powerful hardware and making them accessible to a border range of users and developers.
Data types in deep learning
The corresponding data types used in deep learning frameworks and libraries are FP32 for 32-bit floating-point full precision, FP16, or Bfloat16 for 16-bit half precision, and int8 eight-bit integers.
By default, model weights, activations, and other model parameters are stored in FP32.
FP32 and FP16: Storing a value in FP32 requires four bytes of memory. In contrast, storing a value on FP16 requires only two bytes of memory, so with quantization you have reduced the memory requirement by half.
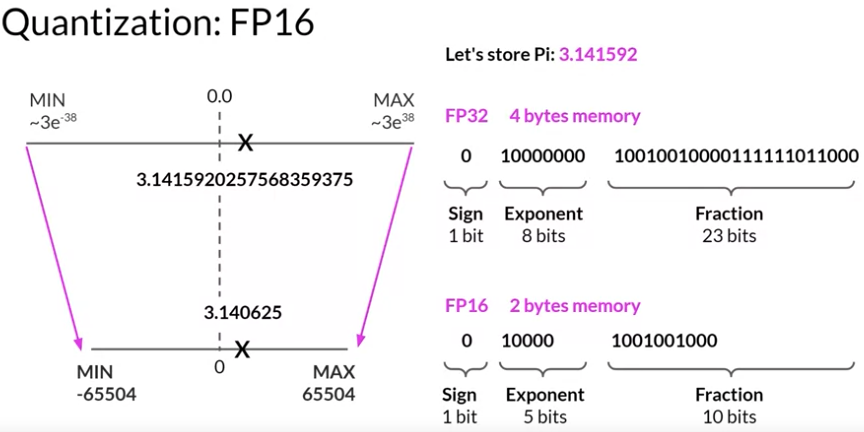

BFLOAT16 : The AI research community has explored ways to optimize16-bit quantization. One datatype in particular BFLOAT16, has recently become a popular alternative to FP16.
BFLOAT16, short for Brain Floating Point Format developed at Google Brain has become a popular choice in deep learning. Many LLMs, including FLAN-T5, have been pre-trained with BFLOAT16. BFLOAT16 or BF16 is a hybrid between half precision FP16 and full precision FP32.
BF16 significantly helps with training stability and is supported by newer GPU’s such as NVIDIA’s A100.
BFLOAT16 is often described as a truncated 32-bit float, as it captures the full dynamic range of the full 32-bit float, but uses only 16-bits.
This not only saves memory, but also increases model performance by speeding up calculations.
INT8: This brings new memory requirements down from originally four bytes to just one byte, but results in a pretty dramatic loss of precision.
Chronology of Quantization in AI
- Early 2000s: Initial ideas around quantization in neural networks begin to surface, but the concept is still in its nascent stage.
- 2015-2016: Research in quantization gains momentum. Papers like “Quantizing deep convolutional networks for efficient inference: A whitepaper” (Raghuraman Krishnamoorthi, 2018) start to emerge, focusing on the potential of quantization.
- 2018-2019: Frameworks like TensorFlow and PyTorch start introducing quantization tools. For instance, TensorFlow Lite introduces post-training quantization.
- 2020-2021: Advanced techniques in quantization, including dynamic quantization and quantization-aware training, become more mainstream, allowing for more effective implementation and minimal loss in model performance.
Quantization Techniques in Neural Networks
Detailed quantization techniques are discussed in this paper: :
“A Survey of Quantization Methods for Efficient Neural Network Inference”
By: Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer (2021)
https://ar5iv.labs.arxiv.org/html/2103.13630
Here is a summary:
1. “Uniform Quantization”: This involves mapping neural network weights and activations to a finite set of values, often represented in a lower precision range. Uniform quantization results in quantized values that are uniformly spaced.
2. “Symmetric and Asymmetric Quantization”: This deals with the choice of scaling factors in quantization, which can significantly impact the performance and accuracy of the quantized neural network models.
3. “Dynamic vs. Static Quantization”: Dynamic quantization involves computing the quantization range dynamically for each activation map during runtime, often leading to higher accuracy. Static quantization, on the other hand, uses a pre-calculated range during inference, which is computationally less demanding but can result in lower accuracy.
4. “Quantization Granularity”: This refers to the level at which quantization is applied, such as layer-wise, group-wise, or channel-wise, each having its own trade-offs in terms of accuracy and computational efficiency.
5. “Non-Uniform Quantization”: A more advanced approach where quantization steps and levels are non-uniformly spaced, potentially achieving higher accuracy for a fixed bit-width.
6. “Quantization-Aware Training (QAT)”: In QAT, the neural network model is re-trained with quantized parameters to adjust for the perturbations introduced by quantization. This approach helps the model to converge with better loss, even with quantized parameters.
You can also find more details in this paper “A White Paper on Neural Network Quantization”
By: Markus Nagel, Marios Fournarakis, Rana Ali Amjad, Yelysei Bondarenko, Mart van Baalen, Tijmen Blankevoort (2021)
https://ar5iv.labs.arxiv.org/html/2106.08295
The authors are delving into these 2 main classes of algorithms:
- Post-training quantization (PTQ)
- Quantization-Aware-Training (QAT)
GPU Capacities in AI
Contribution of GPUs advancements
The advancements in GPU Capacities have played a major role in the success of LLMs on different ways:
Parallel Processing Capabilities:
GPUs are designed for parallel processing, which is ideal for the matrix and vector operations central to deep learning. This parallelism allows for significantly faster processing compared to traditional CPUs, especially in large-scale neural network training and inference.
Enabling Larger Models:
The increase in GPU memory and computational power has directly contributed to the development of larger and more complex AI models, like the GPT and BERT series. These models require substantial computational resources that are only feasible with advanced GPUs.
Reduced Training Time:
Advances in GPU technology have drastically reduced the time required to train complex AI models. Models that used to take weeks to train on CPUs can now be trained in days or even hours on powerful GPUs.
Widespread Accessibility:
The proliferation of powerful GPUs in consumer-grade computers has made AI research and development more accessible to a broader audience, including small startups and academic researchers.
Cloud Computing and AI:
The integration of powerful GPUs into cloud computing platforms has further democratized access to high-end computational resources, allowing users to rent GPU power for AI tasks without needing to invest in expensive hardware.
In summary, GPUs have been critical in making AI more efficient, accessible, and capable, driving forward innovations and applications that are now part of everyday life.
Chronology of GPU Capabilities in AI
2007-2009: NVIDIA introduces CUDA (Compute Unified Device Architecture), allowing GPUs to be used for general-purpose processing (GPGPU). This marks the beginning of using GPUs for AI and deep learning.
2012: Kepler architecture GPUs are released by NVIDIA, enhancing parallel processing capabilities.
2014-2015: NVIDIA introduces the Maxwell and Pascal architectures, which offer significant improvements in terms of power efficiency and computing performance.
2017: The introduction of NVIDIA’s Volta GPU architecture, which includes Tensor Cores specifically designed for deep learning.
2018-2019: Turing architecture is released, introducing Ray Tracing cores and further improvements in AI processing capabilities.
2020-2021: NVIDIA announces the Ampere architecture, which includes the A100 GPU, offering significant advancements in AI and machine learning processing speed and efficiency.
2022: NVIDIA announced the Hopper architecture for its H100, with new Transformer engine: “The H100 accelerator’s Transformer Engine is built to speed up these networks as much as 6x versus the previous generation without losing accuracy”.
Here are some detailed timelines for NVIDIA:
NVIDIA GPU (Modern)
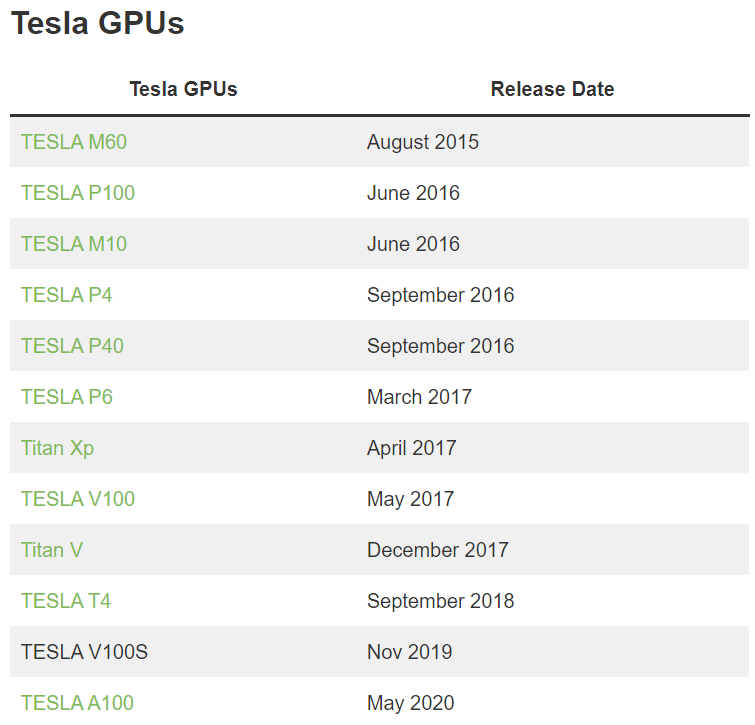
– Tesla GPUs: Starting from Tesla M60 in August 2015 to Tesla A100 in May 2020, and H100 in 2022
– Quadro GPUs: From Quadro P5000 in October 2016 to Quadro P2200 in June 2019.
– GeForce RTX GPUs: Starting with the GeForce RTX 2080 Ti in September 2018, followed by several others like the GeForce GTX 1650 in June 2020
You can find more detailed information in this source: https://exittechnologies.com/blog/data-center/gpu-technology-gpu-history-and-gpu-prices-over-time/
Which GPUs are used for LLMs like GPTs?
Large Language Models (LLMs) like GPT-3 and others are typically trained on high-performance GPUs with high memory bandwidth and large memory capacity to handle the vast number of parameters and computations.
NVIDIA’s Tesla GPUs:
GPUs like NVIDIA’s Tesla V100, A100, and the newer H100 series are commonly used due to their advanced capabilities in handling such tasks.
Cloud-Based GPUs:
Many organizations and researchers utilize cloud-based GPU services for training and deploying LLMs. Cloud platforms like Google Cloud (with TPU and GPU options), AWS (which offers instances with Tesla V100 and A100 GPUs), and Microsoft Azure provide scalable GPU resources that can be particularly useful for large-scale AI model training and deployment.
Examples:
NVIDIA V100 GPUs for GPT-3:
OpenAI’s GPT-3, one of the largest LLMs with 175 billion parameters, was trained using NVIDIA V100 GPUs. Training GPT-3 would cost over $4.6M using a Tesla V100 (32GB version) cloud instance, according to lambdalab.
Source: https://lambdalabs.com/blog/demystifying-gpt-3
NVIDIA H100 GPUs for LLMs:
The NVIDIA H100 Tensor Core GPU, with its Transformer Engine, is specifically optimized for developing, training, and deploying generative AI and LLMs.
In comparative studies, training a 7B GPT model with NVIDIA H100 using FP8 precision was 3x faster than using NVIDIA A100 with BF16 precision, according to a study provided by Mosaic.
The NVIDIA H100 GPUs provide 3.2x more FLOPS for bfloat16 and the new FP8 data type, which is crucial for transformer architecture-based LLMs.
Source: https://www.mosaicml.com/blog/coreweave-nvidia-h100-part-1
“Data centers are becoming AI factories — processing and refining mountains of data to produce intelligence,” said Jensen Huang, founder and CEO of NVIDIA. “NVIDIA H100 is the engine of the world’s AI infrastructure that enterprises use to accelerate their AI-driven businesses.”
Summary
As we’ve seen, AI’s remarkable journey to 2023 is a testament to the power of innovative research and technological evolution, from pivotal research papers on LLMs to the strides in quantization and GPU capabilities. These advancements not only underline AI’s growing role in various sectors but also highlight its potential to continually transform and enrich our everyday experiences.
Glossary
Large Language Model (LLM):
A Large Language Model (LLM) is an advanced type of artificial intelligence model that is designed to understand, interpret, generate, and respond to human language in a way that is both coherent and contextually relevant. These models are “large” both in terms of the size of their neural network architecture and the amount of data they are trained on.
LLMs represent a significant breakthrough in natural language processing (NLP), offering advanced capabilities in understanding and generating human-like text, but they also come with challenges that need to be carefully managed.
Neural Network Architecture:
Neural Network Architecture: LLMs typically use a form of neural network called a transformer, which is particularly good at handling sequences of data, like sentences in a text. The transformer architecture allows LLMs to pay attention to different parts of the input text when generating a response, making them effective at understanding context and generating relevant and coherent text.
NLP
NLP stands for Natural Language Processing, which is a branch of artificial intelligence (AI) that focuses on enabling computers to understand, interpret, and generate human language in a way that is both meaningful and useful. The goal of NLP is to bridge the gap between human communication and computer understanding. NLP includes various tasks like language translation, sentiment analysis, speech recognition, text summarization, question answering, and chatbot functionality. It covers both the understanding (Natural Language Understanding, NLU) and the generation (Natural Language Generation, NLG) of language.
NLP utilizes a variety of methods from linguistics and computer science, including rule-based systems, statistical methods, and machine learning techniques, including both traditional machine learning and deep learning.
What is the difference between LLMs and NLP?
LLMs are a specific type of model within the field of NLP. They are large-scale, deep learning models that have been trained on vast amounts of text data to generate and understand language.
NLP is the broader discipline focused on the interaction between computers and human language, encompassing a range of techniques and tasks, using a variety of methods from linguistics and computer science, including rule-based systems, statistical methods, and machine learning techniques, including both traditional machine learning and deep learning.
While LLMs are specific, sophisticated models within this field, designed for high-level language generation and understanding, using advanced neural network architecture, especially transformers.
What is Generative AI?
Generative AI refers to a subset of artificial intelligence technologies that focus on creating new content or data that is similar to but distinct from the data on which they were trained. This includes generating text, images, audio, video, and other types of media. The “generative” aspect implies that these AI models are not just analyzing or processing existing information but are actually creating new, original outputs.


