In this article, you will learn building a corpus with Wikipedia API in Python and using OpenAI‘s embedding model. The Goal is to prepare the dataset to be used in GPT -3.5 Turbo model, to perform question-answering tasks.
I’m interested here to get the whole articles included in the 2022 FIFA World Cup Category.
Steps to follow:
- Install Wikipedia API ‘wikipedia-api’ and import it ‘wikipediaapi’.
- Build a corpus using Wikipedia API: Gather the articles in Category: 2022 FIFA World Cup. Titles and text in sections and subsections.
- Filter out short text and blanks
- Split inputs in smaller chunks less than 1600 tokens using OpenAI Tiktoken Library
- Use the Embedding model from OpenAI to transform the text inputs to vector embeddings to be used in the GPT-3.5-Turbo model.
Build a corpus using Wikipedia API in Python
Install Wikipedia API
pip install wikipedia-apiImport the library
import wikipediaapiBuild the dataset
Use Wikipedia ‘en’ and the category like this: Category:2022 FIFA World Cup
(https://en.wikipedia.org/wiki/Category:2022_FIFA_World_Cup)
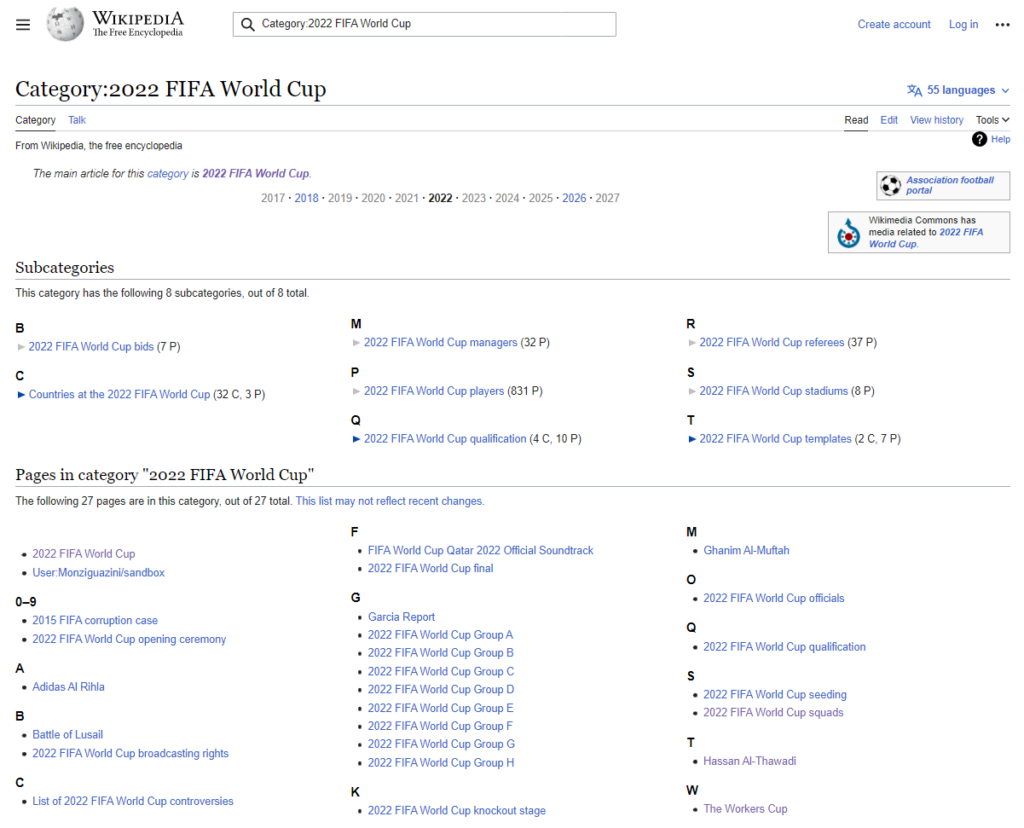
You can see that there are “Subcategories” and “Pages”. The dataset I will be gathering in the following part will be the one coming from “Pages” (You can include “Subcategories” if you want).
Here are the methods I will be using:
def get_sections(
section: wikipediaapi.WikipediaPageSection,
parent_title: list[str],
sections_to_ignore: set[str] = SECTIONS_TO_IGNORE,
) -> list[tuple[list[str],str]]:
"""Gather sections and subsections data."""
sect_title = section.title
title = parent_title
title.extend([sect_title])
results = []
if sect_title not in sections_to_ignore:
sect_text = section.text
string_section = ( title , sect_text)
results.extend([string_section])
if len(section.sections)>1:
for subsection in section.sections:
get_sections(subsection, title, sections_to_ignore)
return results
def get_pages (
page: wikipediaapi.WikipediaPage,
sections_to_ignore: set[str] = SECTIONS_TO_IGNORE,
)-> list[tuple[list[str],str]]:
"""Gather the page information: title and summary, and then go deep in sections information."""
parent_title = page.title
print(f"parent_title = {parent_title} ")
summary = page.summary
string_parent = ([parent_title], summary)
results=[string_parent]
if len(page.sections) > 0:
for section in page.sections:
results.extend(get_sections(section,[parent_title]))
return resultsSECTIONS_TO_IGNORE = [
"See also", "References", "External links",
"Further reading", "Footnotes", "Bibliography",
"Sources", "Citations", "Literature",
"Photo gallery", "Photos", "Gallery",
"Works cited", "Notes", "Notes and references",
"References and sources", "References and notes",
]Then I will be calling the category: 2022 FIFA World Cup
wiki = wikipediaapi.Wikipedia('en')
CATEGORY_TITLE = "Category:2022 FIFA World Cup"
# Get the category object for "2022 FIFA World Cup"
cat = wiki.page(CATEGORY_TITLE)
# Print the name of the category
print("Name: ", cat.categorymembers)
# Get the articles included in this category
# # if it's an article: wikipediaapi.Namespace.MAIN = 0
# # if it's a subcategory: wikipediaapi.Namespace.CATEGORY = 14
articles = [w for w in cat.categorymembers.values() if w.ns == wikipediaapi.Namespace.MAIN]
wiki_corpus=[]
for page in articles:
wiki_corpus.extend(get_pages(page))
wiki_corpus[:5]Here is an overview of the first element on wiki_corpus:
[(['2022 FIFA World Cup'],
"The 2022 FIFA World Cup was the 22nd FIFA World Cup, the quadrennial world
championship for national football teams organized by FIFA. It took place in
Qatar from 20 November to 18 December 2022, after the country was awarded the
hosting rights in 2010. It was the first World Cup to be held in the Arab world
and Muslim world, and the second held entirely in Asia after the 2002 tournament
in South Korea and Japan.This tournament was the last with 32 participating
teams, with the number of teams being increased to 48 for the 2026 edition. To
avoid the extremes of Qatar's hot climate, the event was held during November and
December. It was...")]Prepare the dataset: Tiktoken library
Filter out short text and blanks
def keep_section(section: tuple[list[str], str]) -> bool:
"""Return True if the section should be kept, False otherwise."""
titles, text = section
if len(text) < 20:
return False
else:
return Truewiki_corpus_filtered = [sect for sect in wiki_corpus if keep_section(sect)]Split inputs to chunks less than 1600 tokens
First, you need to install tiktoken and import it.
pip install tiktoken
import tiktokenTo get the number of tokens for each input in our corpus (‘text’), we need to use this function:
def num_tokens(text: str, model: str = GPT_MODEL) -> int:
"""Return the number of tokens in a string."""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))With GPT model been:
GPT_MODEL = "gpt-3.5-turbo"✅ More details of how the split is done for each input in the dataset, is included in this notebook in github embedding_wikipedia.ipynb: https://github.com/MachineLearningBasics/chatgpt_openaiapi
cf methods: split_strings_from_subsection, halved_by_delimiter, num_tokens.
Final split of our corpus:
MAX_TOKENS = 1600
wiki_corpus_final = []
for section in wiki_corpus_filtered:
wiki_corpus_final.extend(split_strings_from_subsection(section, max_tokens=MAX_TOKENS))
print(f"{len(wiki_corpus_filtered)} Wikipedia sections split into {len(wiki_corpus_final)} strings.")109 Wikipedia sections split into 109 strings.Meaning that each input in our corpus has less than 1600 tokens.
Use OpenAI’s embedding model
Now that we have built our corpus, we need to use Embedding to create input features for our GPT-3.5 model.
First, if you don’t have it yet, you need to install openai and create an API KEY.
pip install openai
import openai
openai.api_key=YOUR_API_KEYNow, I will be using the embedding method.
As my corpus is small, I will be using the following code, otherwise you need to create batches to send to OpenAI API, which must not exceed 2046 embedding inputs.
import pandas as pd
# calculate embeddings
EMBEDDING_MODEL = "text-embedding-ada-002"
response = openai.Embedding.create(
model=EMBEDDING_MODEL,
input=wiki_corpus_final
)
embeddings = [e["embedding"] for e in response["data"]]
print(f"length of embeddings array for the whole corpus {len(embeddings)}")
print(f"each embedding has a vector length of {len(embeddings[0])}")
df = pd.DataFrame({"text": wiki_corpus_final, "embedding": embeddings})
df.to_csv("embeddings_2022_fifa_world_cup.csv",index=False)
df.head()length of embeddings array for the whole corpus 109
each embedding has a vector length of 1536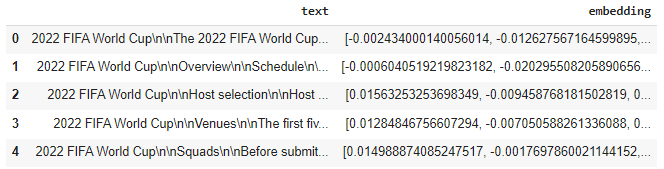
📃 I saved the dataframe to be used later in GPT-3.5-Turbo model questions-answering chat. Read my article to discover how to use this dataframe with GPT-3.5 Turbo model in OpenAI API, and let ChatGPT answers to recent events: Enable ChatGPT Answer Recent Events.
✅ Full version of the notebook here 👉: embedding_wikipedia.ipynb: https://github.com/MachineLearningBasics/chatgpt_openaiapi