You don’t know what is Embedding and how it’s used in OpenAI API ? You are in the right place!
What is Embedding ?
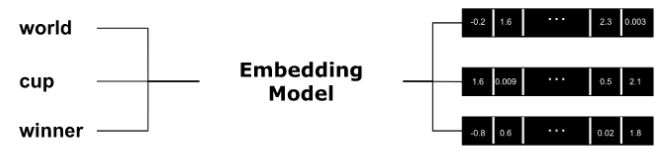
In NLP (Natural Language Processing), embedding is the process of representing words or phrases in a high-dimensional numerical vector space. The word or text embeddings are used to capture the underlying meaning and semantic relationships between words in a text corpus. The goal is that similar words are mapped to nearby points, and dissimilar words are mapped to distant points.
Embeddings are used in various NLP applications, such as text classification, sentiment analysis, machine translation, and question-answering systems.
This latest use case is what I developed in this article:
Word embeddings are learned from large amounts of text data using techniques such as Word2Vec, BERT, or OpenAI model Embedding.
Embeddings are used as input features for machine and deep learning models.
In the following, I will explain how to use the Embedding tool from OpenAI API.
Embedding in OpenAI API
Option 1
The method that we will call using OpenAI API is openai.Embedding.create.
You need first to install openai and create an API Key.
If you don’t know how to do it, read my article:
import openai
openai.api_key='YOUR_API_KEY'
response = openai.Embedding.create(
model="text-embedding-ada-002",
input="Tiktoken library For Tokenization In OpenAI API"
)openai.Embedding.create parameters:
- Model: the one to use for embedding is : text-embedding-ada-002 which is OpenAI’s best embeddings as of Apr 2023.
- Input: The text for which you want to get the embeddings. Each input must not exceed 8192 tokens in length. Here we can use tiktoken library to count for number of tokens we are sending to the model.
Have a look at this article to learn how to use tiktoken library:
The response is a JSON object. You find the embedding vector in response.data[0][’embedding’].
The length of this vector is 1536.
<OpenAIObject list at 0x7ff8e3951f40> JSON: {
"data": [
{
"embedding": [
-0.035191021859645844,
0.002601011423394084,
-0.019024960696697235,
-0.028161657974123955,
... in total there is 1536 elements
-0.025243809446692467,
-0.0176691934466362,
-0.0030854775104671717,
0.004280984867364168,
0.011479818262159824,
-0.02051335945725441
],
"index": 0,
"object": "embedding"
}
],
"model": "text-embedding-ada-002-v2",
"object": "list",
"usage": {
"prompt_tokens": 11,
"total_tokens": 11 } ]}You get the embedding vectors:
embedding = response['data'][0]['embedding']Option 2
Also you can send tokens instead of sending a raw text.
First we need to tokenize the raw text. You can then perform the check mentioned above about the length of tokens (to not exceed 8192 tokens, to be considered by OpenAI models).
import tiktoken
text = "Tiktoken library For Tokenization In OpenAI API"
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
tokens_integer=encoding.encode(text)
tokens_string = [encoding.decode_single_token_bytes(token) for token in tokens_integer]
print("Tokens list", tokens_integer)
print("Back to the raw text:", encoding.decode(tokens_integer))Tokens list [51, 1609, 5963, 6875, 1789, 9857, 2065, 763, 5377, 15836, 5446]
Back to the raw text: Tiktoken library For Tokenization In OpenAI APIThen use the embedding method:
response = openai.Embedding.create(
model="text-embedding-ada-002",
input=tokens_integer
)
embedding = response['data'][0]['embedding']
embedding[:10][-0.035191021859645844, 0.002601011423394084, -0.019024960696697235,
-0.028161657974123955, 0.011531395837664604, 0.018612336367368698,
-0.016917627304792404, -0.0014368193224072456, 0.00019422388868406415,
-0.029900578781962395]Summary
Embedding and tokenization are the first steps to build applications such as question-answering systems that I will be exploring in this article: “How to enable ChatGPT to answer questions related to recent events ?” . As you may know, ChatGPT was trained on data only up until September 2021, so how would it be able to provide answers to queries related to the 2022 World Cup for example?
Tell me in the comments for which application do you intend to use embedding? 👇